集群总览
集群总览页面提供单个 Kubernetes 集群的健康状况与资源使用概览,包含统计卡片、资源图表和近期事件,帮助运维人员快速评估集群状态。
集群总览
集群总览页面提供单个 Kubernetes 集群的健康状况与资源使用概览,包含统计卡片、资源图表和近期事件,帮助运维人员快速评估集群状态。
顶部统计卡片
页面顶部以四列卡片展示核心指标:
- 集群健康 — 显示集群当前状态(运行中、创建中、失败、未知),以及 Ready 和 NotReady 节点数量。
- 总 Pod 数 — 显示集群中 Pod 总数及其中处于 Running 状态的数量。
- 总节点数 — 显示集群节点总数,以及控制平面节点与工作节点的分布。
- 自动缩放 — 显示集群是否启用了 Autoscaling。启用时展示当前工作节点数与最大节点数的缩放区间;未启用时显示"当前为手动扩容"。

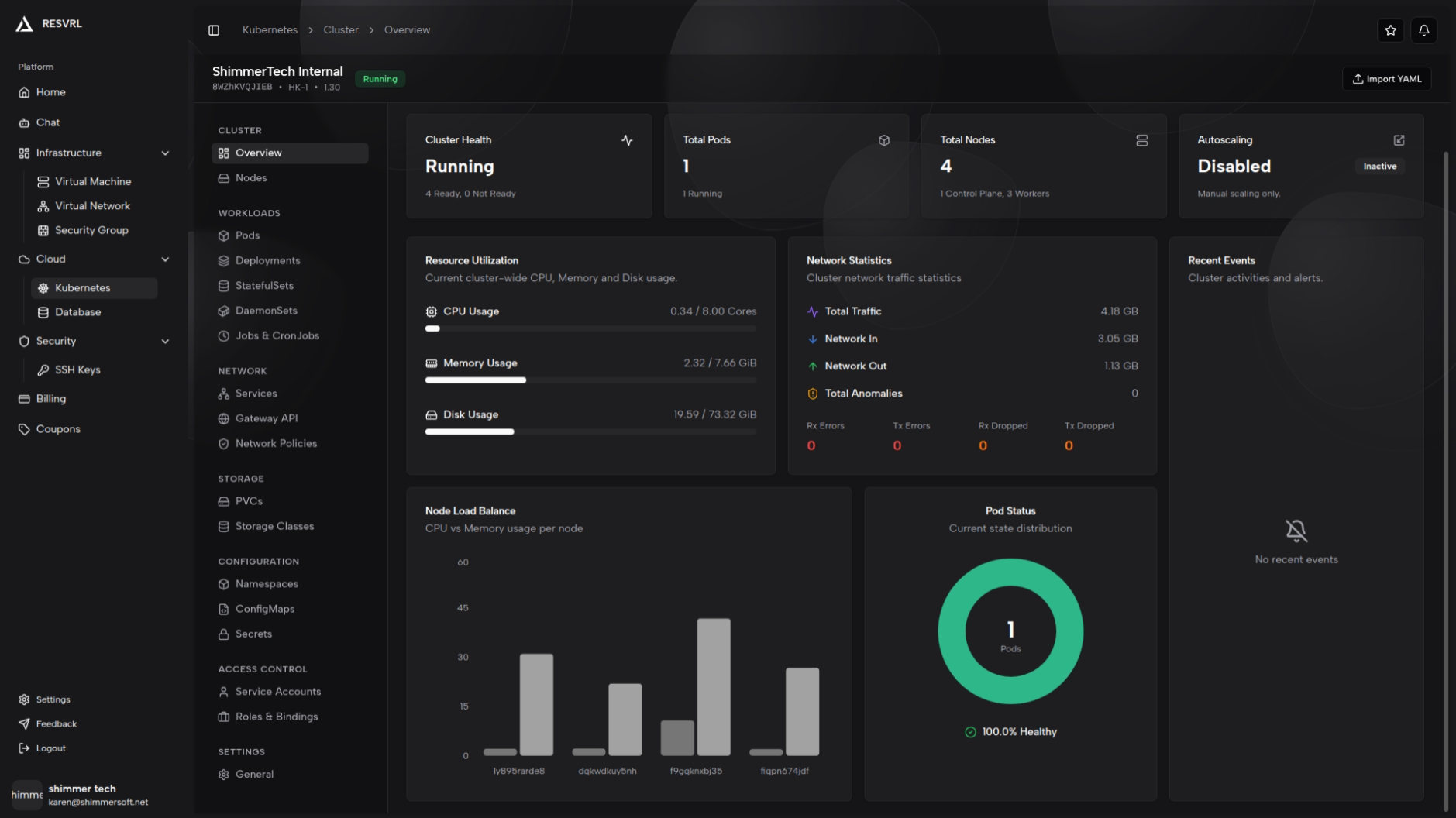
资源利用率
以进度条形式展示 CPU(核心)、内存(GiB)和磁盘(GiB)的当前使用量与集群总容量。每项资源显示具体数值(如 2.50 / 8.00 核心)和对应的使用百分比进度条。
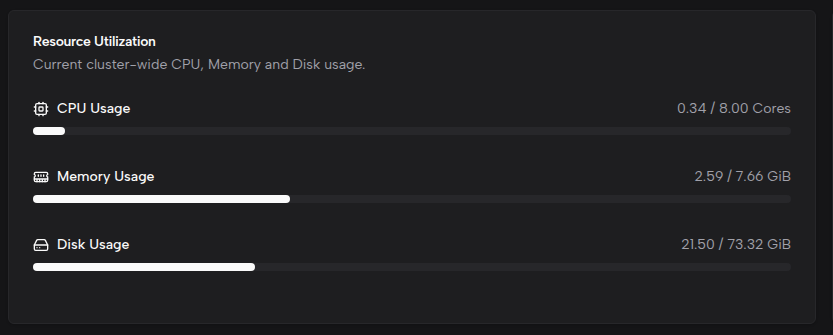
网络统计
展示集群网络流量与异常情况,包含以下指标:
- 总流量 — 入站与出站流量总和(自动格式化为 B/KB/MB/GB/TB)。
- 网络入流量(Rx) — 接收字节总量。
- 网络出流量(Tx) — 发送字节总量。
- 异常总数 — 所有错误与丢包计数的总和。
异常明细以四列网格展示,分别标注颜色:
- 接收错误(Rx Errors) — 红色
- 发送错误(Tx Errors) — 红色
- 接收丢包(Rx Dropped) — 橙色
- 发送丢包(Tx Dropped) — 橙色
错误或丢包计数持续增长时,建议检查集群网络配置和宿主机网络状态。
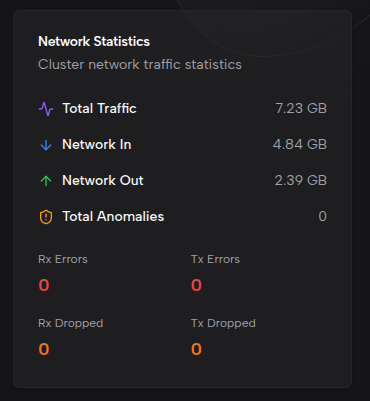
节点负载均衡
以分组条形图展示每个节点的 CPU 与内存使用百分比。每个节点对应两组柱状条,分别表示 CPU 使用率和内存使用率,便于快速识别资源压力较大的节点。
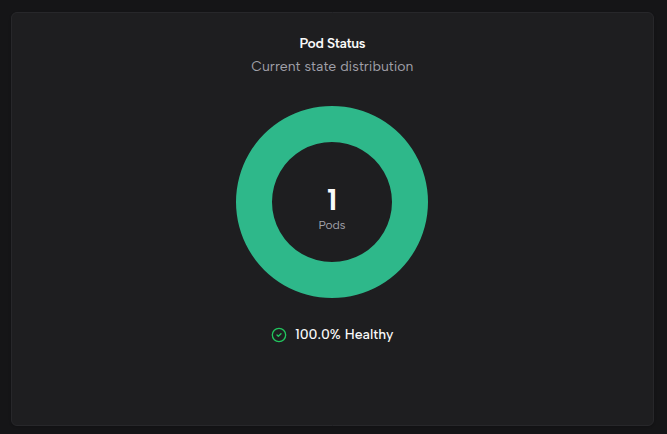
Pod 状态分布
以环形图展示各状态 Pod 的分布:
- Running — 运行中的 Pod
- Pending — 等待调度的 Pod
- Failed — 失败的 Pod
- Unknown — 状态未知的 Pod
环形图中心显示 Pod 总数,底部显示健康比例(Running 状态 Pod 占总数的百分比)。
Pending 状态的 Pod 可能由资源不足或调度限制引起,建议检查节点资源和工作负载配置。Failed 状态的 Pod 需查看具体事件和日志定位原因。
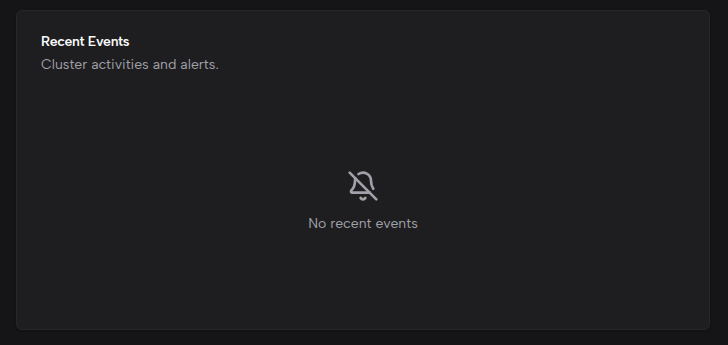
近期事件
列出集群中最近发生的事件,以颜色圆点区分等级:Warning(黄色)和 Normal(蓝色)。每条事件包含消息内容、时间戳、原因和来源组件。列表最多展示 8 条事件。
无事件时显示"暂无事件"的空状态提示。如需查看历史事件,请使用 kubectl 等命令行工具。
注意事项
- 资源利用率(CPU、内存、磁盘)和节点负载图表依赖 metrics-server。若集群未安装 metrics-server,相关指标显示为 N/A,节点负载图表将显示"指标数据不可用"提示。
- 新创建的集群可能需要几分钟才能采集到完整的指标数据。
- 页面数据会自动刷新:集群处于 Creating 或 Deleting 状态时每 5 秒刷新一次,正常运行时每 30 秒刷新一次。
相关文档
本文档更新于 2026-04-25 09:00